Как поставить dav_svn если у вас cpanel
Опять возникла необходимость сделать репозиторий с доступом через http на сервере с cpanel. Ранее я уже об этом уже писал, но половина ссылок в том посте на сегодняшний день уже не работают, поэтому пришлось восстанавливать инструкцию заново, наступая на те же грабли повторно. На этот раз пост без ссылок - просто инструкция шаг за шагом:
Скачиваеме исходники Subversion и распаковываем:
> wget http://subversion.tigris.org/downloads/subversion-1.6.17.tar.gz
> tar -xzf subversion-1.6.17.tar.gz
Скачиваем SQLite распаковываем и копируем в папку с Subversion:
> wget http://www.sqlite.org/sqlite-amalgamation-3.6.13.tar.gz
> tar -xzf sqlite-autoconf-3070701.tar.gz
> cp -r sqlite-3.6.13 subversion-1.6.17/sqlite-amalgamation
Теперь компилируем и устанавливаем:
> ./configure --with-ssl --with-apxs=/usr/local/apache/bin/apxs --with-apr=/usr/local/apache/bin/apr-config --with-apr-util=/home/cpeasyapache/src/httpd-2.0.63/srclib/apr-util
> make
> make install
Создаем репозиторий:
> mkdir /home/username/data
> mkdir /home/username/data/svn
> cd /home/username/data/svn
> svnadmin create --fs-type fsfs repo
Настраиваем конфигурационные файлы апача:
> vi /usr/local/apache/conf/userdata/std/2/username/svn.hostname.com/custom.conf
Содержимое файла:
LoadModule dav_svn_module modules/mod_dav_svn.so
LoadModule authz_svn_module modules/mod_authz_svn.so
<Location /svn>
DAV svn
SVNParentPath /home/svncleve/data/svn
SVNListParentPath on
SVNPathAuthz off
AuthType Basic
AuthName "Private SVN repositories"
AuthUserFile /home/username/svn.passw
Require valid-user
</Location>
Задаем пароль для пользователя SVN:
/usr/local/apache/bin/htpasswd /home/svncleve/svn.passw svnuser
Проверяем конфигурацию сервера, пересобираем конфиги и рестаруем сервер:
/scripts/verify_vhost_includes
/scripts/rebuildhttpdconf
/scripts/restartsrv_httpd
Делаем чистый чекаут на локальной машине:
> svn checkout http://hostname.com/svn/repo .
Если svn update работает хорошо а svn commit выдает 403 ошибку то проверьте .htaccess в document root - cpanel по умолчанию пишет в .htaccess правила, ограничивающие использование методов PUT и DELETE - а именно они как раз и используются в WEBDAW через который работает Subversion. Несколько раз уже на это напарывался.
Обновление прелоадера
Создал английскую версию прелоадера. Обновил внешний вид компонентов.
Теперь не стыдно показывать англоговорящим товарищам.
DNS сервер на домашнем компьютере
Собственный DNS сервер для веб-разработчиков очень удобная вещь. Если локальный компьютер используется для разработки и на нем установлен Apache с несколькими десятками виртуальных доменов то прописывать все виртуальные домены в файле hosts довольно кропотливо. Со временем hosts превращается в полнейшую свалку а собственный DNS сервер позволяет организовать все гораздо компактнее и удобнее.
Обычно, чтобы отличать локальные сайты от всех других я им даю фиксированный суффикс по имени компьютера на котором они крутятся, например: ztools.maxhome - это локальная версия ztools.org на домашенем компьютере, maxistar.maxhome - локальная версия maxistar.ru, ztools.maxbook - версия ztools.org на ноутбуке и так далее.
Рассмотрим пример установки DNS сервера на локальный компьютер под управлением Linux, сделаем так, чтобы ВСЕ сайты с суффиксом .maxhome ссылались на локальный компьютер, с суффиксом .maxbook на ноутбук и так далее.
Итак, имеем машину с Ubuntu, устанавливаем на него DNS сервер:
> apt-get install bind9
добавляем в /etc/named.conf.local следующее:
zone "maxhome" {
type master;
file "/etc/bind/db.maxhome";
};
/etc/bind/db.maxhome - это файл зоны который нам предстоит создать, чтобы не создавать с нуля скопируем один из файлов в папке /etc/bind и отредактируем:
> cp db.local db.maxhome
после редактирования файл выглядит следующим образом (изменения помечены жёлтым):
; BIND data file for local loopback interface ; $TTL 604800 @ IN SOA localhost. root.localhost. ( 2 ; Serial 604800 ; Refresh 86400 ; Retry 2419200 ; Expire 604800 ) ; Negative Cache TTL ; @ IN NS maxhome. @ IN A 192.168.1.101 @ IN AAAA ::1 * IN A 192.168.1.101
Обратите внимание на последнюю строку со звездочкой - она самая главная! Аналогичным образом создаём файлы зон для других компьютеров.
Теперь перегружаем наш DNS сервер:
maxim@maxim-desktop:~$ sudo /etc/init.d/bind9 restart * Stopping domain name service... bind9 [ OK ] * Starting domain name service... bind9 [ OK ]
На всех машинах на которых мы хотим иметь доступ к локальным ресурсам в свойствах сетевого подключения ставим IP адрес машины с установленным DNS сервером в качестве DNS сервера и проверяем как работает:
maxim@maxim-desktop:~$ ping dfdfd.maxhome PING dfdfd.maxhome (192.168.1.101) 56(84) bytes of data. 64 bytes from 192.168.1.101: icmp_seq=1 ttl=64 time=0.044 ms 64 bytes from 192.168.1.101: icmp_seq=2 ttl=64 time=0.050 ms 64 bytes from 192.168.1.101: icmp_seq=3 ttl=64 time=0.044 ms ^C --- dfdfd.maxhome ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2179ms rtt min/avg/max/mdev = 0.044/0.046/0.050/0.003 ms
Теперь любое сочетание символов xxxx.maxhome будет разрешаться на домашний компьютер, причем аналогичным образом можно создать файлы для других компьютеров в нашей домашней сети и всегда будет ясно на каком компьютере какой сайт расположен. Теперь не нужно каждый раз после создания нового виртуального домена редактировать файл hosts на всех компьютерах.
Как поставить автомагнитолу в Hyundai Getz
Штатная аудиоподготовка у Hyundai Getz имеет нестандартный разъем, поэтому, подключить в него магнитолу сразу не получится. Поиск в интернет подсказывает, что для этого лучше всего воспользоваться специальным переходником Hyundai-ISO, который можно купить на Митинском рынке, в Москве. К сожалению, в Саратове нет ни одного Митинского рынка а про переходник не знают даже в специализированных магазинах. Специалисты в сервисе, просто обрезают родные разъемы и скручивают провода как надо, за все удовольствие берут 650-1000 рублей.
Но мне вариант со скручиванием почему то не понравился, да и захотелось самому повозиться :) Я поступил так:
Снял заглушку на месте автомагнитолы при помощи отвертки аккуратно поддев последнюю сверху.
Вынул из разъема магнитолы провода с контактами и вставил эти контакты в оригинальный разъем аудиоподготовки машины предварительно заизолировав до половины изолентой для предотвращения случайного замыкания. Чтобы вынуть контакт из разъема его нужно немного поддеть, например, обычной канцелярской скрепкой или куском проволоки, или же просто посильнее потянуть. Вставляется сам контакт в разъем Hyunday довольно туго - он немного шире чем контакт на разъеме - но плоскогубцы решают все проблемы.
Вот распиновка оригинального разъема на Hyundai Getz:
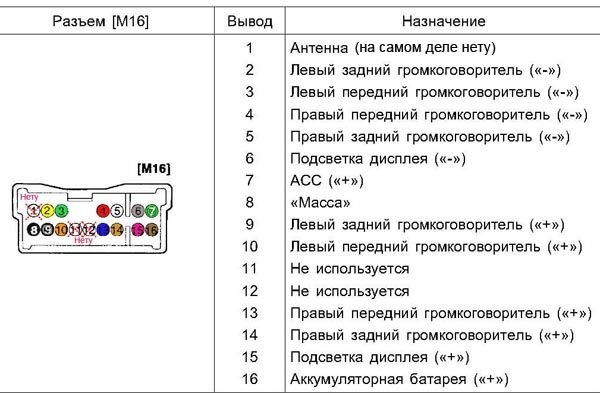
На всякий случай прозвонил разъем тестером - контакт 15 оказался не подсветкой дисплея (+) а скорее землей, поэтому его я не стал использовать.
Распиновка разъема ISO автомагнитолы:
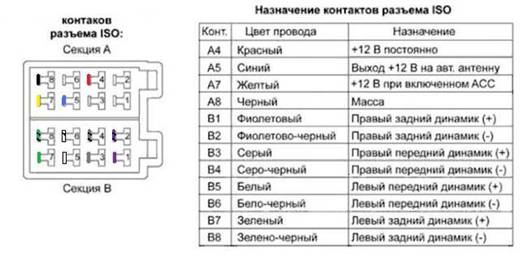
После подключения всех контактов разъем стал выглядить вот так:

После того как самая сложная часть работы осталась позади, вставил антену и поставил магнитолу на штатное место - салазки магнитолы не пригодились - они не влезают. Саму магнитолу зафиксировал обрезками упаковочного вспененного полиэтилена - он отлично гасит вибрации.
Все заработало с первого раза без проблем.
UPD. На схеме разъема M16 изображена ответная часть а не сам разъём - реальный разъем соответственно имеет зеркальное расположение контактов, что без труда видно по форме выемок на разъеме - мне было лень зеркалить изображение разъема - думал это очевидно :) Будьте внимательнее!